Tak on FORTH může běžet takřka na čemkoli

Právě na 6502.org sleduju diskusi o
milliFORTH-6502, který se vejde do 1.110 bytů a vychází z milliForth, který se vejde do 336 bytů (a zbytek už jsou "jen" za běhu dopsaná slova, kterými si definuje vše, co potřebuje), ale oni neřeší RAM za běhu, nýbrž startovní velikost.
Takže minimalizovali na dřeň a i dost základní slova mají jako "high level" definovaná pomocí ještě základnějších (jako 0 1 -1 ... já tam prostě hodil standardní knihovnu a strtoul(buf,&end,BASE) a itoa(c, buf, BASE) a hotovo, všechna čísla od začátku v pohodě, oni si
odvodí pár nezbytných konstant a k číslům se dostanou až o řadu kapitol dál.

)
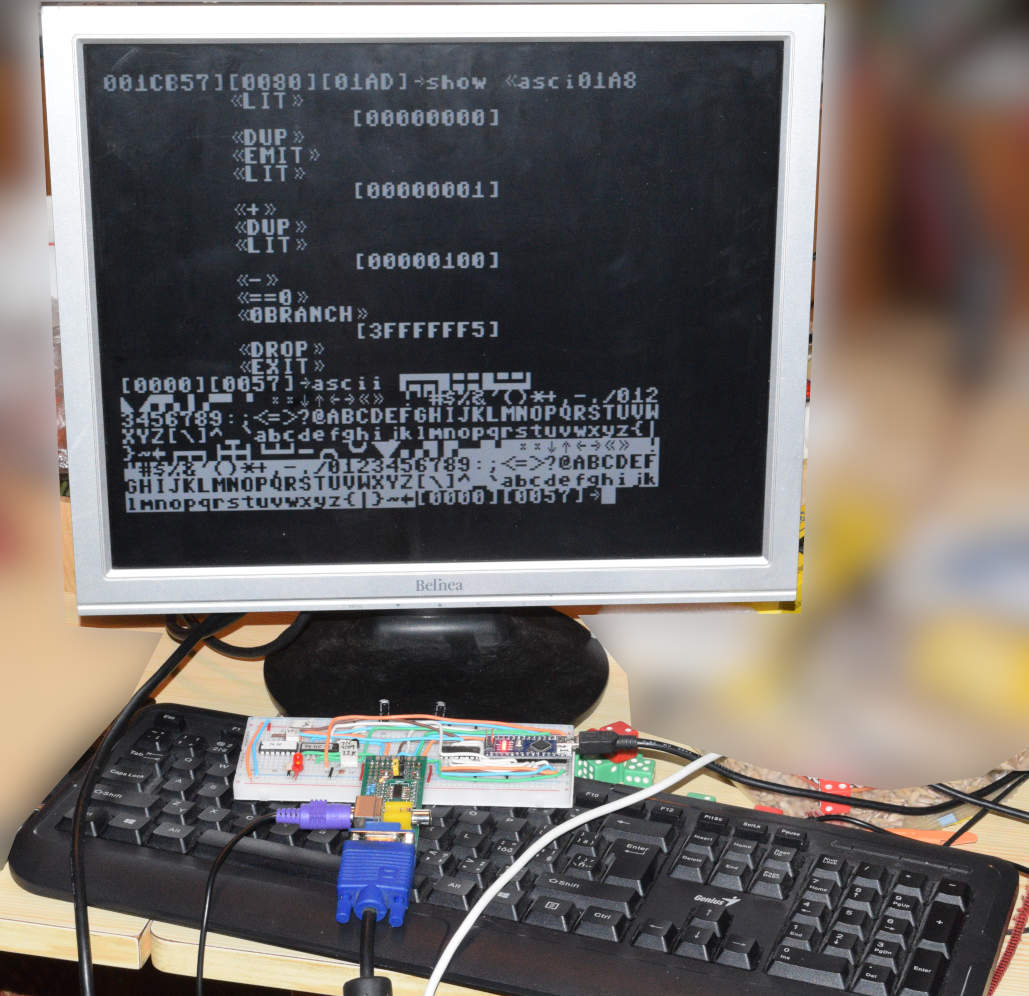
Já tady řeším, že s grafikou, která bere přez 1003 bytů ze 2kB RAM a s tím, že bootstrap je psaný v Céčku a potřebuje systémový zásobník, tam prostě nemůžu "zbytek slovníku" nasypat za běhu, ale potřebuju toho co nejvíc dát předem do FLASH a ten jeden použitelný kilobyte si co nejvíc šetřit a rozplánovat, aby zbylo co nejvíc na finální "improvizování za běhu".
No a ten FORTH se učím právě tím, jak ho implementuju a na to jsem potřeboval, aby mi co nejdřív běželo něco použitelné nějak (tam už skoro jsem) a až pak to začít víc optimalizovat a ztenčovat a rozšiřovat podle potřeby.
Ono i na Arduino jsem už viděl víc implementací, ale nějak mi nesedly, tak si to dělám po svém a mám dobrý pocit z toho, že tomu rozumím a že vím, co které slovo dělá a hlavně proč a k čemu je to dobré
(Z jedné diskuze na 6502.org)
scotws wrote:
... I realized that you don't program in Forth, you use Forth as the foundation of your own programming language based on Forth.
(A může se stát, že se časem a optimalizacema a používáním dostanu k něčemu podobnému, jako ostatní implementace, nebo k něčemu zcela jinému. Ale i kdyby to bylo naprosto stejné, tak rozdíl bude, že všechna slova tam budou za nějakým účelem, k něčemu jsem je potřeboval a použil a vím, co a jak a proč dělají. Což pouhým převzetím cizího kódu nezískám.)

{kind=link}